Abstract
Solving linear differential equations is a common problem in almost all fields of science and engineering. Here, we present a variational algorithm with shallow circuits for solving such a problem: given an \(N \times N\) matrix \({\boldsymbol{A}}\), an N-dimensional vector \(\boldsymbol{b}\), and an initial vector \(\boldsymbol{x}(0)\), how to obtain the solution vector \(\boldsymbol{x}(T)\) at time T according to the constraint \(\textrm{d}\boldsymbol{x}(t)/\textrm{d} t = {\boldsymbol{A}}\boldsymbol{x}(t) + \boldsymbol{b}\). The core idea of the algorithm is to encode the equations into a ground state problem of the Hamiltonian, which is solved via hybrid quantum-classical methods with high fidelities. Compared with the previous works, our algorithm requires the least qubit resources and can restore the entire evolutionary process. In particular, we show its application in simulating the evolution of harmonic oscillators and dynamics of non-Hermitian systems with \(\mathcal{P}\mathcal{T}\)-symmetry. Our algorithm framework provides a key technique for solving so many important problems whose essence is the solution of linear differential equations.
1 Introduction
Linear differential equations (LDEs) describe the dynamics of a plethora of physical models, including classical as well as quantum systems. In many fields of science and engineering, linear differential equations are serving as key roles, such as the Schrödinger equation [1], the Stokes equations [2], and the Maxwell equations [3]. However, solving these LDEs can become a hard problem for a classical high-performance computer, especially when the configuration space has a large dimension, such as in systems of quantum mechanics and hydrodynamics.
Quantum computers have the potential to provide an exponential advantage over classical computers for certain problems. Nowadays, various effective quantum computation protocols emerge, such as the circuit-based quantum computation [4], adiabatic quantum computation [5], and duality quantum computation [6, 7]. Meanwhile, a lot of efficient algorithms for quantum simulation [8, 9], quantum search [10, 11], and algebra problems [12,13,14] have been devised and demonstrated on various quantum devices [15,16,17,18,19,20,21,22,23,24,25,26,27,28]. A scalable quantum computer is expected to be able to obtain the solution of linear systems of equations [29,30,31,32,33,34] and even linear differential equations, exponentially faster than the fastest high-performance classical computers. In the past few years, some efficient quantum algorithms for solving linear differential equations have been proposed [35,36,37], which are based on HHL algorithms or Taylor expansions with linear combination of unitaries. They require complex operations and large number of qubits, making them far from current noisy intermediate-scale quantum (NISQ) [38] devices. In the NISQ era, quantum-classical hybrid algorithms utilize both the performance of classical computers and the intrinsic quantum properties of intermediate-scale quantum systems, leading to lower hardware requirements and robustness against certain noise. These variational algorithms have already provided efficient solutions for quantum chemistry [39,40,41,42], linear algebra [43, 44], and quantum machine learning [45,46,47]. Some of them can be applied to the problem of solving differential equations, whose performance may be highly reliant on the pre-design of ansatz [48] or sufficient qubit resources [49, 50] though.
In this work, we present a quantum algorithm for solving linear differential equations inspired by the quantum-classical hybrid variational methods. We firstly approximate the original problem using difference equations and then transform them into a linear system problem with the assistance of an auxiliary qubit. Then, we split the complete time interval into some slices, and in each slice, there is a Hamiltonian whose unique ground state encodes the solution to the linear equations. These Hamiltonian problems are solved with variational quantum algorithms, and their ground states are also the initial states for the next time slice. Finally, we post-process the output state at the end time point by taking measurement on the auxiliary qubit and then obtain the quantum state encoding the solution from the work qubits. Compared with the previous works, our algorithm requires the least number of qubits, and as for the gate complexity of the trained circuit, the dependence on the system dimension N is logarithmic, keeping same as the existing algorithms. Therefore, our algorithm is compatible with shallow circuits on the NISQ hardware. Moreover, the ansatz circuits are added and trained layerwise, such that they can reflect the feature of stepwise time evolution mastered by differential equations.
This article is organized as follows: In Section 2, we provide a thorough description of our algorithm, including its main framework, detailed optimization procedure, measurement scheme, and complexity analysis. In Section 3, we test this algorithm with a general differential system and show the feasibility of this algorithm framework under different initial conditions and hyperparameters. Then, we apply it to study the dynamics of a harmonic oscillator and non-Hermitian systems with \(\mathcal{P}\mathcal{T}\)-symmetry in Section 4. Finally, a conclusion drawn from this work is given in Section 5.
2 Details of algorithm
2.1 Main framework
We firstly give a detailed description of the problem of concern in this work. Consider the time-varying classical differential equation
where \(\boldsymbol{x}\) and \(\boldsymbol{b}\) are N-dimensional vectors, \({\boldsymbol{A}}\) is an \(N \times N\) diagonalizable matrix that has a decomposition form of linear combination of unitaries: \({\boldsymbol{A}} = \sum _{i=1}^{L} \alpha _i {\boldsymbol{A}}_i\), where \(\alpha _i\)s are complex coefficients and \({\boldsymbol{A}}_i\)s are unitaries that can be efficiently implemented on the quantum device used (such as Pauli-terms, i.e., tensor products of Pauli operators). We assume that L is in the order of \(O(\text {poly}\log N)\), which is valid in many significant physical systems such as molecular systems in quantum chemistry and Ising models. Equation (2) gives out the initial condition of the evolution process dominated by Eq. (1). When \({\boldsymbol{A}}\) is invertible, this equation has an analytical solution at time T:
where \({\boldsymbol{I}}_N\) denotes the \(N \times N\) identity matrix. Many equations of vital physical significance are linear differential equations and we can convert them into the form of the system in Eq. (1) by utilizing methods like spatial finite difference [35]. In this work, we concentrate on the construction of variational quantum algorithm for solving such systems.
According to the Euler method [51], Eq. (1) can be approximately expressed as the following difference equation
where \(\Delta t\) denotes a tiny time step. This conversion holds no matter whether \({\boldsymbol{A}}\) is invertible or not. Therefore, the solution \(\boldsymbol{x}(T)\) at time T can be obtained by iteratively calculating this difference equation, which gives out an approximate solution:
Here \(n = T / \Delta t\) is the number of time steps, which is a hyperparameter having fine control over the precision of the difference algorithm, and the approximation \(({\boldsymbol{A}} \Delta t + {\boldsymbol{I}}_N)^k \approx k {\boldsymbol{A}} \Delta t + {\boldsymbol{I}}_N\) is taken in the \(\boldsymbol{b}\)-term. The approximate solution Eq. (5) is consistent with the analytical one Eq. (3) when \(\Delta t\) is sufficiently small.
In the quantum version of the differential equation problem, the N-dimensional unnormalized solution \(\boldsymbol{x}(T)\) to Eq. (1) is encoded in a normalized quantum state \(|{\boldsymbol{x}(T)}\rangle = \boldsymbol{x}(T) / \Vert \boldsymbol{x}(T)\Vert\). In following contents, notation \(|{\boldsymbol{v}}\rangle\) denotes the corresponding normalized quantum state of arbitrary vector \(\boldsymbol{v}\), i.e., \(|{\boldsymbol{v}}\rangle = \boldsymbol{v} / \Vert \boldsymbol{v}\Vert\). Analogous to the above steps, our algorithm determines the approximate solution by iteratively solving a quantum difference equation. Firstly, we can rewrite Eq. (4) in a linear form
where \({\boldsymbol{M}}\) is a \(2N \times 2N\) invertible upper triangular matrix. We encode the linear system Eq. (8) into a Hamiltonian [43, 44, 52]
where \(\mathbb {P}^{\perp }_{t} = ({\boldsymbol{I}}_{2N} - |{\boldsymbol{y}(t)}\rangle \langle {\boldsymbol{y}(t)}|)\) is the Hermitian operator that projects states into the subspace perpendicular to \(\boldsymbol{y}(t)\), satisfying the idempotent relationship \(\mathbb {P}^{\perp 2}_{t} = \mathbb {P}^{\perp }_{t}\). Therefore, the Hamiltonian H can be rewritten as \(H = {\boldsymbol{\mathcal {M}}}^{\dagger } {\boldsymbol{\mathcal {M}}}\) where \({\boldsymbol{\mathcal {M}}} = \mathbb {P}^{\perp }_{t} {\boldsymbol{M}}\). It is direct to prove that \({\boldsymbol{M}}^{-1} |{\boldsymbol{y}(t)}\rangle\) is the unique ground state of H, corresponding to zero energy.
Consequently, we can solve Eq. (8) by utilizing a variational quantum eigensolver (VQE) [39, 40] to minimize the expectation value of H, which yields a state encoding \(\tilde{\boldsymbol{y}}(t + \Delta t)\), an approximation to \(\boldsymbol{y}(t + \Delta t)\), via parameterized quantum circuits. We discard the component containing \(\boldsymbol{b}\) by measuring the auxiliary qubit and if getting \(\sigma _{z} = 1\), we can obtain the state encoding the approximate solution \(\tilde{\boldsymbol{x}}\) in the work qubits. Meanwhile, the input and the output of the linear system in Eq. (8) take the similar form, the only difference of which is the time they correspond to, so the solution \(\tilde{\boldsymbol{y}}(t + \Delta t)\) can be reused in the next iteration to define the linear system, i.e., be assigned as the right hand side of Eq. (8). Repeat this procedure for \(n = T / \Delta t\) times, and finally, we will get the quantum states encoding the approximated solution \(\tilde{\boldsymbol{y}}(T)\) and hence \(\tilde{\boldsymbol{x}}(T)\). We can also evaluate the expectation values of physical operators for the system and extract other physical information from these states, as demonstrated in Section 4. A schematic of the optimization process of the algorithm is shown in Fig. 1.

The schematic diagram of the optimization procedure of the algorithm. In the \((i+1)\)-th iteration, we use the output state \(|{\boldsymbol{y}_{i}}\rangle\) of the series of trained PQCs \(\mathcal {U}^{(i)}\) as the input state, and optimize the parameters in \(U^{(i+1)}(\boldsymbol{\theta })\) according to \(E(\boldsymbol{\theta })\). Once the optimization process converges, \(U^{(i+1)}\) outputs the state \(|{\boldsymbol{y}_{i+1}}\rangle\), which the approximated solution \(|{\tilde{\boldsymbol{x}}((i+1)\Delta t)}\rangle\) can be extracted from and can be used as the input for the next iteration. Here we decompose the expression of \(E(\boldsymbol{\theta })\) into experimentally obtainable values \(\boldsymbol{\gamma }_{j}\) and \(B_{jk}\). If only the final solution but not the detailed evolution process is of our interest, we can compress the extended series \(\mathcal {U}^{(i+1)}\) to reduce the gate complexity of the final trained circuit
2.2 Details of optimization procedure
Without loss of generality, we can suppose that the dimension of the differential system described by Eq. (1) is \(N = 2^{n_q}\), where \(n_q\) is the number of qubits used to represent the system. There are oracles \(U_{\boldsymbol{x}_0}\) and \(U_{\boldsymbol{b}}\) that can encode the N-dimensional classical vectors \(\boldsymbol{x}_0\) and \(\boldsymbol{b}\) into \(n_q\)-qubit quantum states respectively:
For simplicity, we set the time step \(\Delta t\) to be constant during the algorithm procedure. \(\boldsymbol{x}(t_{n})\) stands for the analytical solution at time point \(t_n = n \Delta t\), and \(\boldsymbol{x}_n\) stands for the corresponding algorithm solution. Similarly, we have \(\boldsymbol{y}(t_n) = (\boldsymbol{x}(t_n); \boldsymbol{b})\) as the encoded theoretical state, and \(\boldsymbol{y}_{n} = (\boldsymbol{x}_{n}; \boldsymbol{b})\) as the encoded state determined by our algorithm.
In the initial iteration, the quantum system starts from an all-zero state. In order to encode \(\boldsymbol{y}_{0} = (\boldsymbol{x}_{0}; \boldsymbol{b})\), an auxiliary qubit \(|{0}\rangle _a\) is introduced. Applying the unitary operator
onto the auxiliary qubit followed by a 0-controlled operator \(U_{\boldsymbol{x}_0}\) and a 1-controlled operator \(U_{\boldsymbol{b}}\), we can initialize the quantum system on the state:
which is taken as the input for our variational quantum eigensolver. The qubit coupled-cluster (QCC) algorithm proposed by I. Ryabinkin et al. [42] is adopted here to build the parameterized quantum circuit (PQC), which is a heuristic method that can automatically choose multi-qubit operations by ranking all Pauli-terms (which are called “Pauli words” in [42]) of given length according to the expectation value of the Hamiltonian. During the procedure of QCC algorithm, a parameterized circuit is optimized to minimize the qubit mean-field (QMF) energy \(E_{\text {QMF}}=\min _{\boldsymbol{\Omega }^{(1)}}\langle \boldsymbol{\Omega }^{(1)}|{H}| \boldsymbol{\Omega }^{(1)}\rangle\), where \(|{\boldsymbol{\Omega }^{(1)}}\rangle\) is the mean-field wavefunction:
Then, the similarity-transformed energy function
is minimized over all possible \(\tau\) values. Since this step can be computationally expensive, \(E[\tau ; P_k]\) is expanded near \(\tau = 0\), and gradients \(\left. \textrm{d} E[\tau ; {P}_{k}] / \textrm{d} \tau \right| _{\tau =0}\) and \(\left. \textrm{d}^2 E[\tau ; {P}_{k}] / \textrm{d} \tau ^2 \right| _{\tau =0}\) are evaluated in order to rank all \(\sum _{i=1}^{l_p} \textrm{C}_{n_q+1}^{i} 3^{i} = O(n_q^{l_p})\) Pauli-terms that act on no more than \(l_p\) qubits and yield non-trivial multi-qubit entanglers. Here \(\textrm{C}_{n}^{m} = n! / [(n-m)! m!]\) is the combination number of picking m elements from a set containing n elements. This step is called “Pauli ranking.” We use the top p terms of ranking to construct the parameterized Pauli entanglers \({U}_P^{(1)}(\boldsymbol{\tau }^{(1)}) = \prod _{j=1}^{p}\textrm{e}^{-\textrm{i} \tau _j P_j / 2}\), and they will be appended into our parameterized quantum circuit to produce the QCC parameterized state \(|{\Psi (\boldsymbol{\tau }^{(1)}, \boldsymbol{\Omega }^{(1)})}\rangle ={U}_P^{(1)}(\boldsymbol{\tau }^{(1)})|{\boldsymbol{\Omega }^{(1)}}\rangle\). \(\{l_p, p\}\) are hyperparameters of the algorithm. The ground state of H and corresponding eigen-energy are obtained by minimizing
Once Eq. (17) is optimized to zero, the parameterized quantum circuit outputs \(|{\boldsymbol{y}_1}\rangle = U^{(1)}(\boldsymbol{\tau }^{(1)}, \boldsymbol{\Omega }^{(1)}) |{\boldsymbol{y}_0}\rangle\), which approximates to \(|{\boldsymbol{y}(\Delta t)}\rangle\) as expounded before. Now we fix the parameters \((\boldsymbol{\tau }^{(1)}, \boldsymbol{\Omega }^{(1)})\) and use this output state of the initial iteration as the input state of the second iteration.
Therefore, with the time evolution in each small time step being approximated by our method, the output state after the k-th time step is
which provides a good approximation of \((\boldsymbol{x}(k \Delta t); \boldsymbol{b})\). For the final step, we measure the \(\sigma _{z}\) value of auxiliary qubit. If the output is zero, the work qubits will be on the state \(|{\tilde{\boldsymbol{x}}(T)}\rangle\); otherwise, the PQC will be executed until the measurement of the auxiliary qubit outputs zero. Note that the parameterized circuits in our algorithm are added and trained step by step, which corresponds to tiny time steps of evolution in the difference method. We will show below that the combination of the layerwise optimization process and the difference approximation can reduce the requirement of qubit resources and restore the entire evolutionary process.
2.3 Measurement scheme
In this part, we give a discussion about how to perform the measurements in the optimization process. For a PQC scheme \(U(\boldsymbol{\theta })\) with \(\boldsymbol{\theta }\) denoting the parameters to be optimized in a certain stage of our algorithm, which can be a QMF ansatz or QCC ansatz, we measure the Hamiltonian H to obtain its expectation value, and if gradient-based optimizers are employed, we need to take the gradients \(\partial \langle {H}\rangle / \partial \boldsymbol{\theta }\) by analytically differentiating \(U(\boldsymbol{\theta })\) [44] or using parameter shift [45, 53, 54] to update the parameters. Note that when the time step \(\Delta t\) is sufficiently small, matrix \({\boldsymbol{M}}\) in Eq. (6) can be approximated as
Considering the linear decomposition of \({\boldsymbol{A}}\), \({\boldsymbol{M}}\) can also be further represented by a set of \((n_q + 1)\)-qubit unitaries (\({\boldsymbol{I}}\) stands for the \(2 \times 2\) identity matrix):
When running our algorithm on real quantum devices, we can divide the task of evaluating \(E(\boldsymbol{\theta })\) into many experimentally implementable measurements according to the following relationship
where \(|{\boldsymbol{y}_{n+1}(\boldsymbol{\theta })}\rangle = U(\boldsymbol{\theta }) |{\boldsymbol{y}_{n}}\rangle\), \(B_{ij} = \langle {\boldsymbol{y}_{n} | U^\dagger (\boldsymbol{\theta }) {\boldsymbol{M}}_i {\boldsymbol{M}}_j U(\boldsymbol{\theta }) | \boldsymbol{y}_n}\rangle\) and \(\boldsymbol{\gamma }_{i} = \langle {\boldsymbol{y}_{n} | U^\dagger (\boldsymbol{\theta }) {\boldsymbol{M}}_i | \boldsymbol{y}_{n}}\rangle\). \(B_{ij}\)s and \(\boldsymbol{\gamma }_{i}\)s can be measured by the quantum circuits in Fig. 2a and b.
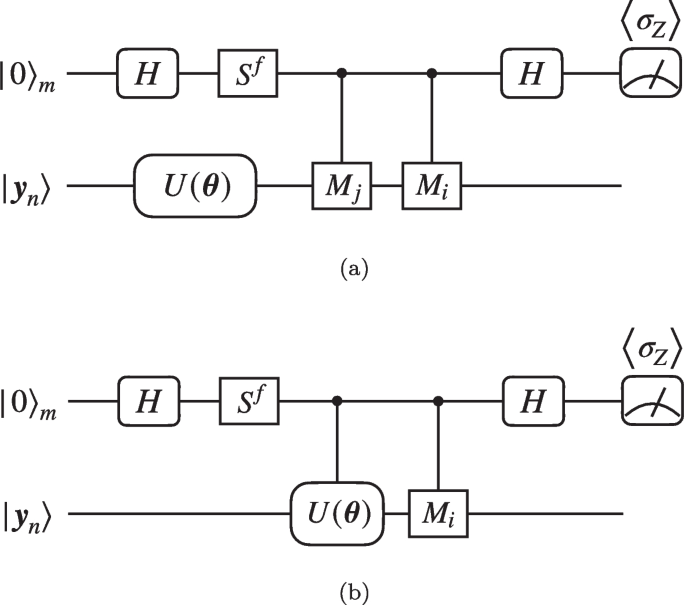
Quantum circuits for evaluating the values of a \(B_{ij} = \langle {\boldsymbol{y}_{n} | U^\dagger (\boldsymbol{\theta }) {\boldsymbol{M}}_i {\boldsymbol{M}}_j U(\boldsymbol{\theta }) | \boldsymbol{y}_n}\rangle\) and b \(\boldsymbol{\gamma }_{i} = \langle {\boldsymbol{y}_{n} | U^\dagger (\boldsymbol{\theta }) {\boldsymbol{M}}_i | \boldsymbol{y}_{n}}\rangle\) based on the measurement results of the auxiliary qubit. Here the controlled gates are applied when the auxiliary qubit is on \(|{1}\rangle _{m}\)
In the circuit for computing \(B_{ij}\), as shown in Fig. 2a, the Hadamard test [44] is employed, which requires one more auxiliary qubit \(|{0}\rangle _m\). \(S = \text {diag}(1, \textrm{i})\) is the phase shift gate and the flag f is either 0 or 1, determining whether the real part or the imaginary part of \(B_{ij}\) is to be evaluated. The probability of obtaining \(+1\) when we perform \(\sigma _{z}\) measurement on the auxiliary qubit is
Hence, we can evaluate \(B_{ij}\) terms as
When \({\boldsymbol{A}}_i\)s are Pauli-terms (as well as \({\boldsymbol{M}}_is\)), since \(B_{ij}\) is essentially the expectation value of \({\boldsymbol{M}}_i {\boldsymbol{M}}_j\) of state \(|{\boldsymbol{y}_{n+1}(\boldsymbol{\theta })}\rangle\), we can construct Hermitians from \({\boldsymbol{M}}_i {\boldsymbol{M}}_j\) and measure them on the quantum state directly, which does not require the auxiliary qubit \(|{0}\rangle _{m}\) and is detailed in Appendix 1.
Similarly, circuit in Fig. 2b can output the real parts and imaginary parts of \(\boldsymbol{\gamma }_{i}\)s respectively, according to
from which we have
Because of the symmetry of \({\boldsymbol{B}}\), i.e., \(B_{ij} = B_{ji}^*\), in general, \((3 + 4L) (3 + 4L + 1) / 2 = O(L^2)\) circuits for B and O(L) circuits for \(\boldsymbol{\gamma }\) are required. Note that the measurement is only applied on the auxiliary qubit under \(\sigma _{z}\) bases, which is experimentally friendly.
2.4 Complexity of the algorithm
In our algorithm, two main approximations are adopted. One is using difference equations to reduce the original differential system, as in Eqs. (6), (7), and (8). The other is using Eq. (19) to avoid evaluating matrix inversion. Both are 2nd-order approximations, which implies that the local truncation error of this algorithm is \(O({(\Delta t)^2})\). Therefore, our algorithm is a 1st-order finite-difference method, i.e., the global error \(\epsilon\) is \(O(\Delta t)\). As long as \(\Delta t\) is sufficiently small, the algorithm solution will be close enough to the analytical result. The detailed derivations of local and global errors are provided in Appendices 2 and 3. In Appendix 4, we also discuss the error resulting from imperfect VQE optimization.
Qubit complexity of our algorithm is \(\log _2 N + 2\) according to the circuit design described previously. This is the least qubits complexity required in quantum LDE solvers, since we need at least \(\log _2 N\) qubits to encode N-dimensional vectors if there are no specific constraints on matrix \({\boldsymbol{A}}\), e.g., \({\boldsymbol{A}}\) being sparse. We need one auxiliary qubit to encode state \(|{\boldsymbol{y}}\rangle\), and another one for measuring elements of matrix B and vector \(\boldsymbol{\gamma }\) to evaluate the expectation of Hamiltonian in Eq. (9). Similar to our work, Berry et al. [36] solve Eq. (1) by discretizing them, but the converted difference equations at different time points are encoded in a single large linear system, indicating that more qubits are required for all time slices. Specifically, although qubit complexity of the algorithm is weakly affected by \(\epsilon\), which is \(O(\log (N \log (1/\epsilon )))\), the constant addition term in complexity is proportional to \(\log (T\Vert {\boldsymbol{A}}\Vert )\). Therefore, given a matrix \({\boldsymbol{A}}\), the number of qubits required by the algorithm grows as the complete evolution time T gets longer. Recently, a work for solving d-dimension Poisson equation was also proposed [49]. Its spirit is similar to the discretizing method in [36], but it utilizes variational quantum algorithms to solve the encoded large linear system. Analogously, the algorithm for solving partial differential equations in [50] discretizes the variable domain with \(2^n\) grid points and \(2^m\) interpolation points and encodes \(2^{n+m}\) function values directly into an \((n+m)\)-qubit state which is constructed from a PQC. These algorithms require more qubits for finer discretization and hence higher accuracy, while our demand for qubit resources keeps constant for ordinary equations of certain differential order. Xin et al. [37] solve Eq. (1) by discretizing them using Taylor expansions of the analytical solution and require \(O(\log (1/\epsilon ))\) more auxiliary qubits to perform the linear combination of unitaries.
Once all \(n = T / \Delta t \sim O(1 / \epsilon )\) iterations are accomplished, the resulting circuit will be a series of PQC blocks:
where \(\boldsymbol{\theta }^{(k)} = (\boldsymbol{\tau }^{(k)}, \boldsymbol{\Omega }^{(k)})\). With reference to the structure of our ansatz, we can conclude that the gate complexity of the finally trained circuit \(\mathcal {U}\) is \(O(\frac{1}{\epsilon } n_q) = O(\frac{1}{\epsilon } \log N)\), which has the same logarithmic dependence on the system dimension N as existing algorithms. However, the dependence on \(\epsilon\) is not optimal. We owe this to the balance between space complexity and time complexity of our LDE algorithms. Besides, \(\mathcal {U}\) can restore the complete dynamical process of system evolution: we can extract the sub-circuits of \(i \sim j\) slices in \(\mathcal {U}\) for arbitrary i, j, and the yielded sub-series \(\prod _{k=j}^{i} U^{(k)}\) reflects the evolution of \(\boldsymbol{y}(t)\) during time interval \([i \Delta t, j \Delta t]\). Moreover, if only the final solution \(|{\boldsymbol{y}(T)}\rangle\) but not the detailed evolution process is of our interest, we can check the length of \(\mathcal {U}^{(i)}\) before each time step, and if there are more than \(n_g\) gates, circuit optimization technologies in [55] can be employed to compress them into \(n_g\) gates. Therefore, in the final circuit \(\mathcal {U}^{(n)}\) the number of quantum gates will also be limited in \(O(n_g)\). Here \(n_g\) is a hyperparameter that should be determined with the compress fidelity guaranteed.
An estimation of the number of queries to quantum gates during the entire training process is provided in Appendix 5. It is worth noting that in order to make approximation (19) effective, \(\Delta t\) must be restricted by \(\Vert (\Delta t {\boldsymbol{A}})^2\Vert \ll \Vert \Delta t {\boldsymbol{A}}\Vert\). Therefore, we can select a \(\Delta t\) satisfying \(\Delta t \ll 1 / \Vert {\boldsymbol{A}}\Vert\), where \(\Vert {\boldsymbol{A}}\Vert\) is the 2-norm of \({\boldsymbol{A}}\).
3 Example models
We apply our algorithm to several linear differential equations to show how well it can solve classical systems dominated by equations as Eq. (1). We first consider an ordinary complex matrix
with initial conditions
We set the time interval as \(\Delta t = 0.1\) and the number of time steps as \(n = 100\), to get the solution at \(T = 10\). At the end of i-th time step, we simulate the optimized PQC \(\mathcal {U}^{(i)}\) and evaluate the overlap at \(t = i \Delta t\) by
Here \(|{\boldsymbol{x}_{\text {alg}}(i \Delta t)}\rangle = |{\boldsymbol{x}_{i}}\rangle\) is the output state of \(\mathcal {U}^{(i)}\), and \(|{\boldsymbol{x}_{\text {ana}}(i \Delta t)}\rangle = |{\boldsymbol{x}(i \Delta t)}\rangle\) is the normalized analytical solution. Meanwhile, overlaps between the output state of PQC and the final analytical solution \(f_i^{\text {alg}} {:=} |\langle {\boldsymbol{x}_{\text {ana}}(T) | \boldsymbol{x}_{\text {alg}}(i \Delta t)}\rangle |\) and overlaps between the analytical solution at current time and the final analytical solution \(f_i^{\text {ana}} {:=} |\langle {\boldsymbol{x}_{\text {ana}}(T) | \boldsymbol{x}_{\text {ana}}(i \Delta t)}\rangle |\) are also calculated. These metrics are also called fidelities, time evolution of which are shown in Fig. 3. From the curve of \(f_i\) (red dashed line), we can see that our algorithm can effectively simulate the evolution of linear differential equations, keeping the instantaneous overlaps between the algorithm states and the corresponding analytical solutions higher than 98%. High instantaneous overlaps mean that our algorithm can keep high fidelities during the whole evolution process (i.e., in all intermediate time slices of [0, T]), while the high final value of overlap \(f^{\text {alg}}_i\) indicates that the algorithm can obtain the ideal final result. Meanwhile, by comparing the complete curves of \(f^{\text {alg}}_i\) and \(f^{\text {ana}}_i\) in Fig. 3 (deep blue solid line and light blue dashed line respectively), we can conclude that our algorithm can keep consistent with the analytical metric values during the whole evolution process.

Time evolution of fidelities (i.e., overlaps) for linear differential system defined by Eqs. (29) and (30). Here \(|{\boldsymbol{x}_{\text {alg}}(t)}\rangle\) and \(|{\boldsymbol{x}_{\text {ana}}(t)}\rangle\) stand for the solution given out by the PQC in our algorithm (abbr. “alg”) and the analytical solution (abbr. “ana”) at time t respectively. The element values of the state vectors at the beginning of evolution \((t = \Delta t = 0.1)\) and at the end of evolution \((t = T = 10)\) are displayed in the lower-left and upper-right subfigures, where \(x_{i} (i=0,1)\) is the i-th element of \(|{\boldsymbol{x}}\rangle\)
Moreover, in order to demonstrate the applicability of our algorithm under different initial conditions, we keep the definition of \({\boldsymbol{A}}\) as Eq. (29) and simulate the algorithm to solve equations with \(|{\boldsymbol{x}_0}\rangle\) and \(|{\boldsymbol{b}}\rangle\) being
where \(\alpha = n\pi /5,\ \beta = m\pi /5,\ n, m \in \{0, 1, \cdots , 5\}\). We set the target time \(T = 5\) and the time step \(\Delta t = 0.1\). By varying the values of n and m, we calculate the difference between the final overlap \(|\langle {\boldsymbol{x}(T) | \boldsymbol{x}_{N}}\rangle |\) and the ideal expectation, as shown in Fig. 4. The average value of final errors over all initial conditions is less than 0.0014, which means that the feasibility of our algorithm can still be maintained under different initial conditions.

The errors of the final optimization results under different initial conditions of the differential system defined by Eq. (29)
Also, for the purpose of studying the algorithm performance under different values of time step \(\Delta t\), the most important hyperparameter, we keep the conditions in Eq. (29) and Eq. (30) unchanged, while we set the evolution time \(T = 10\), and tune \(\Delta t\) from 0.05 to 0.95. For each \(\Delta t\), we calculate the averaged fidelity at i-th step by
which characterizes the overall precision of our algorithm during the whole training process. With discrete \(\mathcal {F}_{i; \Delta t}\) data collected, three-dimensional interpolation based on multi-quadric radial basis function is performed, generating an interpolation function \(\mathcal {F}(T, \Delta t)\) in the domain \([0, 10]_{T} \times [0.05, 0.95]_{\Delta t}\), which is plotted as the surface in Fig. 5. It is clear that if evolution time T or time step \(\Delta t\) takes small value, our algorithm can produce solution state at high fidelity. As \(\Delta t\) increases, the fidelities decline faster in the training process, which can be concluded from the slope towards large T-large \(\Delta t\) direction in Fig. 5. In general, we can define an algorithm-effective area in parameter space satisfying \(0< T \Delta t < \delta\), where \(\delta\) is a fidelity-related parameter and a smaller value of \(T \Delta t\) can lead to a better optimization result.

Time averaged fidelities in training processes for different \(\Delta t\). The target differential system is defined by Eqs. (29) and (30). Yellow dots are the original \(\mathcal {F}_{i; \Delta t}\) data points. The three dimensional surface represents the interpolation function \(\mathcal {F}(T, \Delta t)\). The square contour figure in the T-\(\Delta t\) plane is the projection of \(\mathcal {F}(T, \Delta t)\) surface
4 Applications
Above we have discussed the algorithm with an ordinary complex matrix from the perspective of mathematics and demonstrate the feasibility of our scheme under different parameter conditions. In this section, we apply our algorithm to the dynamical simulation of different real physical processes.
4.1 One-dimensional harmonic oscillator
The first physical model is the one-dimensional harmonic oscillator, whose displacement x(t) is governed by a second order differential equation:
where the intrinsic frequency \(\omega\) only depends on the system. This equation can be converted into first order differential equations by introducing variable substitution \(x_1 = x,\ x_2 = \dot{x}\). Therefore we have:
We define a vector \(\boldsymbol{x}(t) = (x_1(t), x_2(t))^{\textrm{T}}\), and write it in the form of Eq. (1) and Eq. (2) as
which has an analytical solution:
We tested our algorithm for \(\omega = 1.5\), and the initial conditions are \(\boldsymbol{x}(0) = (0, 1)^{\textrm{T}}, \boldsymbol{b} = \boldsymbol{0}\), which corresponds to the motion of a one-dimensional harmonic oscillator initially located at the coordinate origin with unit velocity. We set the time step \(\Delta t = 0.1\). Our algorithm produces vectors highly consistent with analytical solutions. Note that the algorithm vectors are normalized, and the normalization factor c(t) can be determined by
where \(E_0 = (\dot{x}^2(t) + \omega ^2 x^2(t)) / 2 \equiv ({x}_{0}^{\prime 2} + \omega ^2 x_0^2) / 2\) is the constant total energy if we assume the oscillator has unit mass, \(r(t) = |x_2(t)/x_1(t)|^2 = |\bar{x}_2(t)/\bar{x}_1(t)|^2\) is the ratio of the probabilities for the work qubit at different states, and \(\bar{x}_i(t) = x_i(t) / c(t) \ (i = 1,2)\). Therefore, the kinetic energy and the potential energy are evaluated as
and their evolution with time is shown in Fig. 6, which displays a behavior of sine functions with period \(\sim 2\pi /3\) as expected in theory. It can be seen that the error of energy accumulates with time, which is a natural result of finite difference method according to the discussion in Section 2.4 and Appendix 3.
Such an example for solving second order differential equation shows that our algorithm can be applied to find solutions to those higher-order differential equations by converting them into first-order linear differential equations.

a Time evolution of potential energy and kinetic energy for the one dimensional harmonic oscillator. b The energy difference between analytical (abbr. “ana”) and algorithm (abbr. “alg”) results. c The element values of the final state vectors (at \(T = 10\)) corresponding to analytical evaluation and algorithm solution
4.2 Non-Hermitian systems
In this part, we discuss the application of our algorithm to the dynamical simulation of non-Hermitian systems with \(\mathcal{P}\mathcal{T}\)-symmetry. In 1998, Bender found that Hamiltonians satisfying joint parity (spatial reflection) symmetry \(\mathcal {P}\) and time reversal symmetry \(\mathcal {T}\), instead of Hermiticity, can still have real eigenvalues. When the Hamiltonian commutes with the joint \(\mathcal{P}\mathcal{T}\) operator, it is classified as a \(\mathcal{P}\mathcal{T}\)-symmetric Hamiltonian. If eigenstates of the \(\mathcal{P}\mathcal{T}\)-symmetric Hamiltonian are also the eigenstates of \(\mathcal{P}\mathcal{T}\) operator, \(\mathcal{P}\mathcal{T}\)-symmetry is unbroken, while the symmetry is broken conversely [56]. The transition between these two phases in parameter space happens at so-called exceptional points or branch points [56, 57]. There are many novel physical phenomena shown up in this kind of systems, such as the violation of no-signaling principle [58], the symmetry breaking transition [59], \(\mathcal{P}\mathcal{T}\)-symmetric quantum walk, and characters of exceptional point [60]. Especially, it is shown that the entanglement can be restored by a local \(\mathcal{P}\mathcal{T}\)-symmetric operation [61,62,63], which can not be observed in the traditional Hermitian quantum mechanics.
We consider a coupled two-mode system (coupling strength s) with balanced gain and loss (\(\lambda s\)), which can be regarded as a \(\mathcal{P}\mathcal{T}\)-symmetric qubit with Hamiltonian:
where \(\sigma _{i}\ (i=x,y,z)\) are Pauli matrices and the positive parameter \(\lambda\) represents the degree of non-Hermiticity in the system. The energy gap of the Hamiltonian \(\omega =2s\sqrt{1-\lambda ^{2}}\) will be real as long as \(\lambda <1\), meaning that the \(\mathcal{P}\mathcal{T}\) symmetry is unbroken, in which cases the Hamiltonian keeps invariant under \(\mathcal{P}\mathcal{T}\) transformation: \((\mathcal{P}\mathcal{T})H_{\mathcal{P}\mathcal{T}}(\mathcal{P}\mathcal{T})^{-1}=H_{\mathcal{P}\mathcal{T}}\), where the operator \(\mathcal {P}=\sigma _{x}\) and \(\mathcal {T}\) corresponds to the operation of complex conjugation. On the other hand, \(\lambda > 1\) will lead to a broken phase with a transition at exceptional point \(\lambda _{\textrm{ep}}=1\).
Suppose that there is another qubit, which is entangled with the \(\mathcal{P}\mathcal{T}\)-symmetric qubit and they form Bell state \((|{01}\rangle + |{10}\rangle )/\sqrt{2}\) initially. To investigate the dynamic process of the two-qubit non-Hermitian system, we take \(\boldsymbol{x}(t)\) to represent the quantum states. Comparing the evolution equation of this non-Hermitian quantum system with Eq. (1), we can determine that
Here we take \(\hbar = 1\) for simplicity, and s is set to be one. We use our algorithm to solve the differential equations of state evolution and monitor the degree of entanglement by concurrence [64], which is defined as
where \(\rho =|{\boldsymbol{x}(t)}\rangle \langle {\boldsymbol{x}(t)}|\) is the density matrix of the two-qubit system, and \(\mu _{i}\)s are the eigenvalues of \(\rho (\sigma _{y} \otimes \sigma _{y})\rho ^{*}(\sigma _{y} \otimes \sigma _{y})\) in descending order.
The numerical simulation results are shown in Fig. 7 and the configuration of simulation is detailed in Appendix 6. We can conclude that the entanglement decays exponentially to zero in the symmetry-broken phase (\(\lambda = 2.0\)), while the entanglement oscillates with time in the unbroken phase (\(\lambda = 0.5\)), indicating the entanglement restoration phenomenon induced by the local \(\mathcal{P}\mathcal{T}\)-symmetric system. As for the case at \(\lambda = 0.99\), the temporal period of concurrence becomes so long that the evolution displays a decay-like behavior in limited time, conforming to the properties of near-exceptional points. These results are consistent with theoretical expectations.

a Evolution of concurrence in the two-qubit entangled system with local \(\mathcal{P}\mathcal{T}\)-symmetry under different degree of non-Hermiticity. b The errors between analytical and algorithm results
In this example, the evolutionary process restored by our algorithm reveals interesting physics that is unable to be observed in the traditional Hermitian quantum mechanics. That is the increase of entanglement during a specific time interval (\(t \in [1.8, 3.0]\)) in the unbroken phase of \(\mathcal{P}\mathcal{T}\)-symmetry. If we just concentrate on the initial state (\(t = 0\)) and the final state (\(t = 3.0\)), only the relative reduction in concurrence can be concluded, and we cannot observe the entanglement restoration process [61].
5 Conclusion
In this work, we propose a hybrid quantum-classical algorithm for solving linear differential equations. The spirit of the algorithm is a first-order finite difference method, with solution vectors well encoded into quantum states. For an N-dimension system, our algorithm only requires one auxiliary qubit and \(\log N\) qubits to encode the solution, and another auxiliary qubit to assist in measuring Hamiltonian expectations, which is optimal compared with the previous works. The gate complexity is also logarithmic in N, presenting similar dependence on system dimension as existing algorithms. We demonstrate the algorithm with a general differential system and present its effectiveness and robustness under different initial conditions and hyperparameters. Furthermore, we apply the algorithm to the dynamical simulation of different physical processes, including a one-dimensional harmonic oscillator system and \(\mathcal{P}\mathcal{T}\)-symmetric non-Hermitian systems. Our work provides a new scheme for solving linear differential equations with NISQ devices and the protocol can also be demonstrated on practical quantum computation platforms. It is worth mentioning that the qubit coupled-cluster method is employed in our framework as the VQE sub-program for solving ground state problems. However, it is still an open question to choose more adequate eigensolvers for specific systems and we leave it in future works.