Introduction
Evolution of linear systems could be implemented with repeated action of linear operators. In finite-dimensional systems with randomness, the evolution may be computed with multiplication of random matrices. As a result, in diverse fields of science and engineering [1,2,3,4,5,6,7], random matrix products show up ubiquitously and have been a hot subject for intensive study for a long time [1]. In certain cases, the investigation is extended to the study of random products of operators as a generalization to infinite dimensions [8,9,10].
Among different aspects of random matrix products, the computation of the growth rate of their norms is of fundamental importance [1, 11, 12], which is related to the spectra of random oscillator chain [3, 13], the density of states in a disordered quantum system [4, 14,15,16,17] or the famous Anderson localization [18, 19]. However, few cases exist which can be solved with an exact analytic computation [11]. A common practice remains to be Monte carlo simulation which is easy to implement and thus used widely [1, 2, 20,21,22]. It is undoubtedly a good way to get a quick estimation of the growth rate. However, as well known, the convergence of the Monte carlo computation is slow, which in many cases prevents an accurate evaluation, especially when the growth rate is small. For good accuracy, sometimes cycle expansions could be used to extract the growth rate but its implementation quickly becomes rather involving if the number of the sampled matrices is large [23, 24]. To obtain analytic dependence on parameters, various perturbative techniques may be applied to get approximations such as the weak or strong disorder expansion [11, 25, 26]. Nevertheless, most of their application is focused on low-dimensional matrices and the computation sometimes turns out very technical even for low-order expansions [11].
In a recent paper [27], we proposed a generating function approach for the evaluation of growth rates of random Fibonacci sequences, which is very efficient and good for both analytic or numerical computation. Later on, the method is extended to random sequences with multi-step memory and a conjectured general structure in the generating function iteration is proved [28]. As the random sequence is a special case of random matrix products [1], it is thus tempting to see if this new formalism could be further extended. In the most general case, we succeeded in deriving such a new formulation along the previous line but with interesting new elements, which will be presented in this paper. Two methods of different sophistication for a perturbative expansion are proposed and demonstrated in a plethora of examples, where analytic expansions or even exact expressions in certain cases for growth rates are conveniently derived, for matrices with various dimensions or with different distributions.
The paper is organized as follows. In section 2, a general formulation of the random matrix product problem is proposed based on the generating function approach. In the next two sections, two different methods are suggested for the evaluation of growth rates based on the new formulation. The first one is a direct method which is easy to implement but somewhat restricted, to be discussed in section 3. The other one is an approach based on invariant polynomials which is more general but more involved, to be detailed in section 4. In these sections, both the analytic and the numerical computation is carried out and compared to check the validity of the new formulation. Then in section 5, the technique is applied to the calculation of the free energy of a random Ising model. Finally, problems and possible future directions are pointed out in section 6.
Formulation based on the generating function
Here, after a brief review of the generating function technique in the evaluation of the grow rate of a random Fibonacci sequence, we reformulate the problem with 2×2 random matrices to give a taste of the new method. Then, a very general formulation is presented, which is good for random matrices of any dimension or with any probability distribution.
A brief review of the generating function approach to stochastic sequences
In a previous paper [27], we used a generating function approach to treat the generalized random Fibonacci sequence
where the plus or the minus sign is picked up with equal probability, and β>0 is a parameter controlling the size of the random term. In most cases, |xn|∼ exp(λn) for n→∞, where λ is the growth rate of the random sequence, which could be positive indicating a growth or negative indicating a shrinkage of the magnitude of a typical term in the sequence in the asymptotic limit. The zero value of λ usually signifies a phase transition [21]. In [27], we proposed a generating function which calculates λ as
where {gn(x)}n=0,1,2,⋯ is a sequence of generating functions which satisfy the recursion relation
with g0(x)= ln(1+x)2. The actual evaluation of the growth rate could be done either numerically or analytically by virtue of Eq. (3). One pleasant surprise is that for β small a direct expansion in β can be obtained trivially by a Taylor expansion of gn(0) with small n
For example, the expansion (4) is obtained with n=3. Interestingly, the above formulation could be extended to a stochastic sequence with n-step memory [28]. Here is an example with 3−step memory
where β,γ>0 and the plus or minus sign is taken with equal probability. Similar expressions for the growth rate and the recursion relation are obtained, which enables a convenient derivation of an asymptotic expansion of the growth rate as well for small β and γ [28]. As we know, a stochastic sequence problem could be formulated in the form of random matrix products [1, 21, 23]. For example, the generalized random Fibonacci sequence could be written as
where Yn=(xn,xn−1)t is a 2−d vector and
samples two possible matrices with equal probability in the iteration. However, generally, it is not possible to write a random matrix product as a stochastic sequence. One natural question is whether the above formalism for computing growth rate could be further extended to a general matrix. How about random matrices with more complex distributions? We have positive answers to all these questions as demonstrated below.
Generating function for 2-d matrix products
To illustrate the computation, we first consider a special case: a 2-d matrix product with a simple distribution. The random matrix An in Eq. (7) is a special case of the following
where the plus sign is taken with probability p and the minus sign with 1−p. The matrix before the plus minus sign is the major part of the random matrices since both matrices reduce to it when β=0. Similar to the case of a stochastic sequence, a family of generating functions could be defined by the recursion relation
with the starting function
The maximum Lyapunov exponent (MLE) is then \(\lambda ={{\lim }_{n\to \infty }}f_{n}(0)\). Similar to the definition in random sequences, MLE is the growth rate of the products of random matrices. Note that when the parameters take appropriate values in Eq. (8) (a=c=r=1,b=d=e=g=h=0,p=1/2) we recover the equations for the random Fibonacci sequence. It is easy to see why the functions defined by Eq. (9) and Eq. (10) are good for computing the MLE. In the argument of the logarithm in Eq. (10), the constant and the coefficient of x could be viewed as the first and second component of a 2−d vector Y1 (see Eq. (6)). The two logarithms in Eq. (10) encodes the random vector Y1=A0Y0, where A0 is either of the matrices in Eq. (8) and Y0=(1,0)t is the initial vector. Thus we obtain Y1=(a+βe,c+βg)t with probability p and Y1=(a−βe,c−βg)t with probability 1−p which is encoded by the two terms in Eq. (10). Similarly, all the Yn’s are encoded in the logarithmic terms in fn−1(x) and the iteration Eq. (9) corresponds to the matrix multiplication Eq. (6), which produces all the possible Yn+1’s, with appropriate weight. In each logarithmic term that is present in fn+1(x), the argument is in fact a ratio of linear functions of the components of Yn+1 and its preimage Yn. The coefficient before the logarithm is the probability for this ratio to occur.We ues the following example to give a more detailed explanation.
In the first logrithmic term of Eq. (11), the argument is a ratio of two linear functions of x. In the denominator, we see the components of Y1 and those of Y2 in the numerator. Four possible values for Y2 are embedded in the four logarithmic terms of f1(x) with the probabilities p2,p(1−p),(1−p)2,(1−p)p. Depending on the value of x, the argument gives different ratios and the function f1(x) is a weighted sum of logarithms of these ratios. If we take x=0, the argument is the ratio of the first components of consecutive random vectors; if x=1 is taken, the argument is the ratio of the sums of the two components. In general, the arguments of the 2n+1 logarithms in fn(x) give all possible such ratios. With n→∞, the magnitudes of these ratios will approach a stationary distribution and the coefficients before the logarithm are the corresponding probabilities. Thus, fn(0) appoaches the MLE [20, 27, 28]. From the argument above, it can also be seen that in the limit n→∞, the function fn(x) will approach a constant - the MLE, almost everywhere.
Generating function for general matrix products
The above argument could be easily extended to the general case: the set of (k+1)×(k+1) matrices B(α) with a sampling probability P(α), where k is a positive integer and α denotes different samples in the matrix space, being discrete or continuous. As before,each (k+1)−dim vector a=(a1,a2,⋯,ak+1)t could be encoded by a linear expression
where z2,⋯,zk+1 are formal variables to encode the components of the vector. To encode the random products, each matrix B(α) corresponds to a transformation T(α) defined as
where
with the convention \(z_{1}=1,\tilde {z}_{1}=1\). In this notation, the recursion relation could be written as
where again P(α) denotes the sampling probability of the matrix B(α). The starting function is
and as before the MLE could be obtained as
As we mentioned earlier, the MLE is the growth rate of the products of random matrices. If the distribution is discrete, the integration in Eq. (15) should be replaced by a summation. Note that Eq. (17) is exact and the problem that remains is the evaluation of fn(z) in the limit n→∞. As explained in [27, 28], the recursion relation could be used directly in a numerical computation. In the presence of small parameters, various expansion techniques could be developed as demonstrated below with different levels of sophistication. The first one is a direct expansion which is simple to use but has certain restrictions to be detailed below. The second one applies in the general case while the calculation is more involved.
Direct expansion
In section 2.1, we see that the expansion in β is easily carried out to high orders just by several iterations of the recursion relation. This crisp feature could be maintained if the matrix A has a special structure. We will give several examples in the following to illustrate this point. To see the validity of the derived analytic expressions, Monte Carlo simulation is used for comparison. Each MLE is generated by carrying out one million Monte Carlo steps.
Expansion for 2-d matrices
To verify the validity of our procedure, we use the 2×2 matrices below
In the above equation, if b=μa,d=μc, the argument substitution in Eq. (9) becomes x→μ±βR(x), where R(x) is a rational function of x. Thus, each additional iteration gives a higher order expression of λ in β when β is small.
More explicitly, if we take
where the plus or the minus sign is taken with equal probability, i.e. p(+)=p(−)=0.5, then a few iterations with Eq. (9) in view of Eq. (17) result in
In Fig. 1(a), the expansion Eq. (20) is compared with the results from the Monte carlo simulation. When β<0.3, the two agree very well while the error rises quickly after β=0.35. Especially, the valley at β∼0.42 is not present in the analytic result. This is because the expression Eq. (20) is an asymptotic one and is only valid for small β.
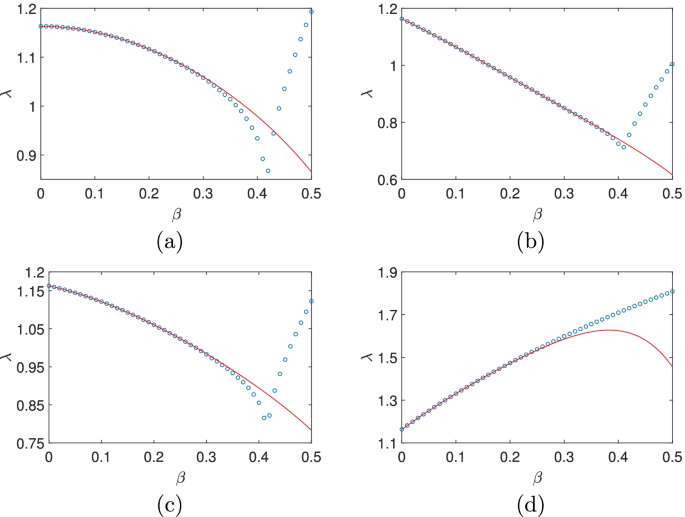
(Color online) The dependence of the MLE on β for different probabilities p of taking the plus and minus sign in Eq. (19). (a) p=0.5,0.5;(b) p=0.2,0.8;(c) p=0.4,0.6;(d) the result for the system with Eq. (24). The Monte carlo results are marked with (blue) circles while the analytic approximation is plotted with (red) solid line
It is easy to see that in Eq. (20) there are only even powers of β since the plus or the minus sign is taken with equal probability and nothing changes if we change the sign of β. With different probabilities, e.g., p(+)=0.2,p(−)=0.8, we have
which is plotted in Fig. 1(b) and matches well with the simulation result. Here, in the expression Eq. (21), both even and odd powers of β are present as expected. To further see the trend, we take p(+)=0.4,p(−)=0.6 which gives
being plotted in Fig. 1(c). From the above three plots and more plots not shown, we see that one singularity emerges near β∼0.42, almost independent of the probability distribution. Also, the analytic result agrees with that of the simulation in a region of decreasing size as p(+) increases which is probably related to the positiveness of all the elements in the two matrices in Eq. (19). Also, as p(+) approaches 0.5, the absolute values of the coefficients of the odd powers of β become smaller and smaller and vanish at β=0.5 while those of the even powers rise considerably.
To check the validity of the method in more complicated cases, we consider the following situation
where
and p(1)=1/6,p(2)=1/6,p(3)=2/3. Our iteration gives
which is plotted and compared favourably with the numerical result in Fig. 1(d). In all the examples above, the absolute values of the coefficients approximately increase exponentially with the powers of β which indicates a finite radius of convergence of the asymptotic expansion.
Expansion for 3-d and 4-d matrices
Our scheme is independent of the dimension of the involved matrices. Below, we show the computation on the 3×3 or 4×4 matrices. Here, we give one example for each case.
If we take the 3d matrices to be
with p(+)=p(−)=0.5, then the MLE is
As before, the symmetry in the plus and minus sign results in the presence of only even powers of β. As shown in Fig. 2(a), the analytic result Eq. (27) matches well with the numerical result when β<0.38. If we take p(+)=0.4,p(−)=0.6, then
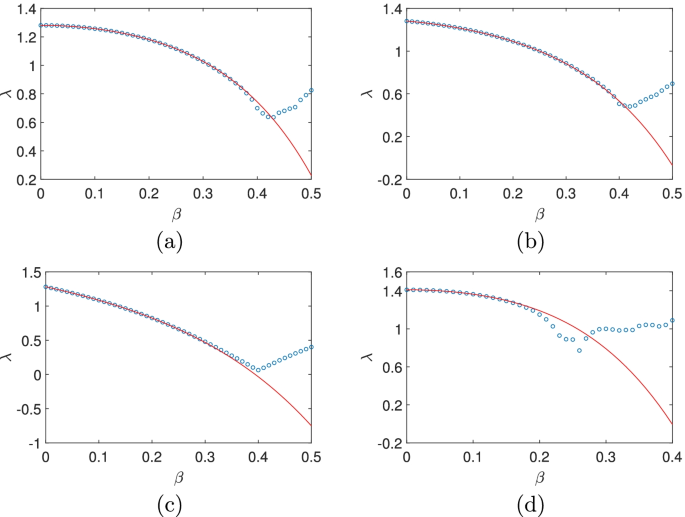
(Color online) The dependence of the MLE on β. For Eq. (26) with (a) p(+)=p(−)=0.5; (b) p(+)=0.4,p(−)=0.6; (c) p(+)=0.1,p(−)=0.9; (d) For the system given by Eq. (30) with p(+)=p(−)=0.5. The Monte carlo results are marked with (blue) circles while the analytic approximation is plotted with (red) solid line
which is plotted in Fig. 2(b). If we take p(+)=0.1,p(−)=0.9, then
which is plotted in Fig. 2(c). From Eqs. (27),(28) and (29), we see that the absolute values of the coefficients of the odd powers in the expansion increase with the decrease of p(+), while the validity domain of the expansion increases. The location of the singularity is more or less stable in the figure where the simulation result bends off the analytic approximation.
In the 4d case, we take
with p(+)=p(−)=0.5. The MLE is then
which is plotted in Fig. 2(d) together with the numerical result. From the figure, we see that the validity region of Eq. (31) reduces again compared to the 2d or 3d cases. Also, the dependence on β becomes quite complex after β∼0.2.
In all the above computations, in order to carry out the computation, the β−independent part of the matrix has a very special form, which may be considered as a limitation of the method. However, in practice, for a fixed β, we are always allowed to freely choose that part of the matrix by properly adjusting the random parts. The real problem is how to choose a good one to make a quick convergence of the expansion. An empirical hint is to make the stochastic part as small as possible.
Direct expansion for continuous distribution
We use one example to demonstrate the application of the current technique to matrices with continuous distribution. With the specific matrices and distribution below, we are able to derive an exact analytic expression of λ, which could be used to explain the failure of the asymptotic expansion.
We use the following 2×2 matrices
and the distribution of β is assumed to be uniform in the interval [0,α] with
for a given α>0. The substitution Eq. (14) becomes
In this particular case, after one iteration, the variable z2 in the expression fn disappears and thus fn becomes a constant. In other words, an exact expression of λ is obtained as
and its direct expansion around α=0 is
The above two solutions are plotted in Fig. 3 and compared with the results from the Monte Carlo simulation. It is easy to see that the exact result matches well with the Monte carlo simulation for all α. Nevertheless, the asymptotic expansion starts to deviate near α∼1, due to the truncation of high order terms. So, the singularity at α=1 in the logrithmic function plays a central role in the convergence of the asymptotic series here. Even though the convergence is very good for small α, near the singularity the expansion could totally go awry, which may also explain the sudden explosion of the error in the asymptotic expansion in Figs. 1 and 2.
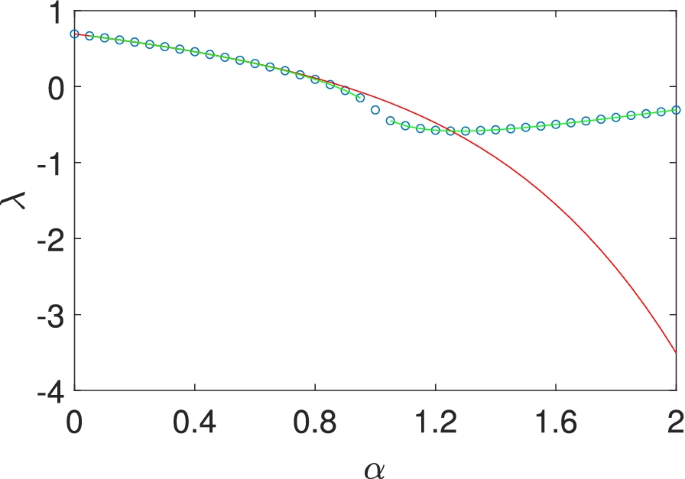
(Color online) The dependence of the MLE on α for the system described by Eq. (32). The Monte carlo result is marked with (blue) circles while the exact one is plotted with (green) solid lines. The analytic approximation is plotted with (red) solid lines
Computation based on invariant polynomials
Below, the major deterministic part of the random matrix A is denoted as A0, which is the matrix for β=0. As explained before, although the direct expansion technique is fast and convenient, it could be a problem to extract a proper matrix A0 with the required special structure. In this section, a more sophisticated expansion based on invariant polynomials is introduced to cope with this difficulty.
A general formulation
In the study below, the matrix A0 is always considered to be diagonalizable. For simplicity, we assume that this has already been done and
where λi’s are eigenvalues of A. With this simplification, the substitution in Eq. (13) is greatly simplified. Especially, the deterministic part of \(\tilde {z}_{i}\) (see Eq. (14)) becomes λizi/λ1,i=2,3,⋯,k+1. If we assume that all zi’s are small, all \(\tilde {z}_{i}\)’s could essentially be approximated by polynomials of {zi}i=2,⋯,k+1 up to a given order m. In fact we can do a Taylor expansion of the denominator of Eq. (14) to the order m to get these polynomials. The starting Eq. (16) could also be expanded to the same order, i.e., we may start with an m-th order polynomial
where the short-hand notation i is a collective index for {i2,⋯,ik+1} and
With the polynomial substitution and the ensuing truncation to the m-th order, the polynomial fn(z) will approach a stationary form which is invariant under the iteration, since |λi/λ1|<1 and the random term B(α) is assumed small.
Alternatively, we may assume that the polynomial f0(z) in Eq. (37) is already invariant and seek for appropriate coefficients ai. Upon one iteration, these coefficients become \(\tilde {a}_{i}\) that are linearly related to the original coefficients, i.e.
where C is the transformation matrix that depends on the random matrices B(α) and their sampling rates. The invariance condition predicts that C has 1 as its dominant eigenvalue and the absolute values of all other eigenvalues are smaller than 1. The corresponding left eigenvector L and right eigenvector R could be obtained by solving the linear equation
where δij is the Kronecker delta function.
The starting function Eq. (16) could of course be expanded into a polynomial form with the coefficient vector bi, which could be written as a linear combination of right eigenvectors. Upon iterations, with the assumed spectral property of matrix C, the first mode remains intact and all the other ones decays to zero. As a result, the final stationary coefficient vector \(\bar {b}_{i}\) is the projection of the starting vector bi to the first eigenvector which can be computed as
From Eq. (17), the constant term \(\bar {b}_{0}\) in the invariant polynomial gives the MLE. In fact, it is not hard to see that the right eigenvector could be taken as Ri=δi0, corresponding to a zeroth order polynomial, which is obviously invariant under the iteration. Therefore,
which will be checked in several examples below.
Two examples
Here, we give two examples for the application of the method of invariant polynomials. For simplicity, we assume that when β=0, the major part of the matrix is already in a diagonal form. In the two dimensional case, we take
with p(+)=p(−)=0.5. A direct application of the above scheme gives the growth rate
where only even powers of β are present due to the sign symmetry mentioned previously. A comparison of the computation from Eq. (44) and from numerical computation is displayed in Fig. 4(a). It is easy to see that the two results agree very well in the whole computational region. In the case of 3×3 matrices, we try
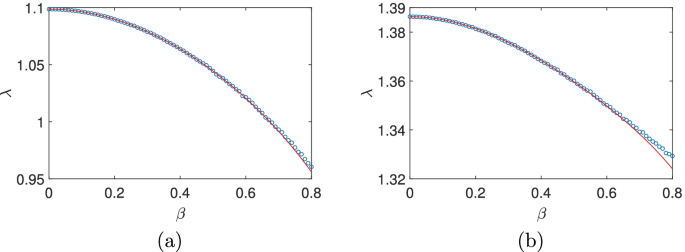
with p(+)=p(−)=0.5. The maximum Lyapunov exponent is
which is plotted in Fig. 4(b) together with the numerical profile. The two agree quite well until β∼0.7, which nicely confirms the validity of our new scheme based on invariant polynomials.
Application to the Ising model with random on-site fields
In this section, we apply our method to the one-dimension Ising model with random on-site field. In this model, N spins lay side by side along a one-dimensional lattice, each of which has two possible states: the spin up state (σi=1), or the down state (σi=−1). Following the terminology in [1], we may write down the Hamiltonian of the system
where J is the coupling constant between nearest-neighbor spins and hi is the external magnetic field on each site, being assumed to be random. The first term in Eq. (47) describes the interaction of neighboring spins and the second term takes into account the potential energy in the external field. The partition function is
Introducing the transfer matrix
or more explicitly
with a periodic boundary condition, the free energy per spin could be written as
The equations above provide a general frame of computing the free energy of the 1-d Ising model using the transfer matrix approach. An exact analytic expression may be derived if the external field is constant over the sites. In the presence of local randomness, the external field hi is a quenched random variable, differing from site to site, for which it is hard to get an exact solution. When the interaction is strong, an analytic expansion is easily derived with our method. First, we reshape Eq. (50) as follows
with \(x_{i}=e^{-2\beta h_{i}}\) and ε=e−2βJ, being small and to be used as the expansion parameter. When the reshaped Li is used in Eq. (51), the free energy could be written as [1]
\(\overline {h}\) is the average of hi over different sites. Once the distribution of ε is given, the first and the second term in Eq. (53) are obtained directly. What is left to do is a proper estimation of the third term. Since the major part of the third term is diagonal, we may directly apply our method to compute
For simplicity, we assume a uniform distribution of xi in (0,1), i.e. P(x)=1. Other forms of distributions can equally be used in our formulation while the resulting quadrature may not be computed analytically. The variable substitution Eq. (14) looks simple now
and the starting function has a integral form
since the distribution is continuous. The method of invariant polynomials may be applied here by expanding Eq. (55) and (56) into polynomials of proper order depending on the desired accuracy. For example, if the expansion is carried out to the sixth order, we may obtain
the leading order of which agrees with that in [1] for this particular distribution. In Fig. 5, we see that the analytic result matches well with the numerical one when ε<0.3. The free energy of the system reads
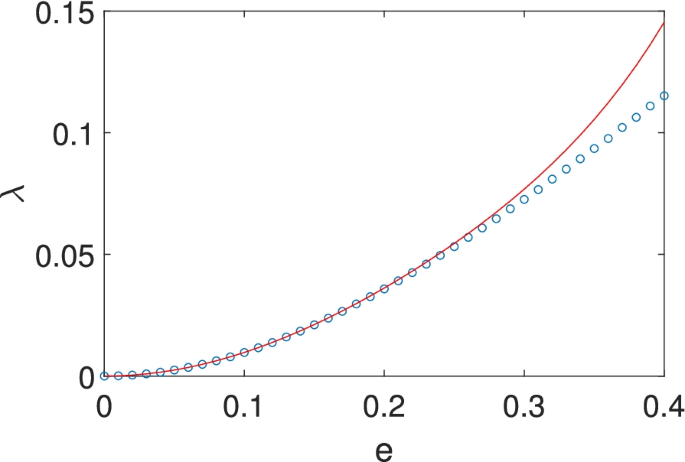
(Color online) A comparison of the analytic approximation with the numerical simulation for Eq. (57). The Monte carlo results are marked with (blue) circles while the analytic approximation is plotted with (red) solid line
The Taylor expansion is valid only when ε is small so that Eq. (58) is a good approximation for J large enough.
Discussion and conclusions
In this paper, we generalize the generating function approach developed in [27, 28] for dealing with stochastic sequences to the treatment of random matrix products. After a general formalism is introduced, two analytic schemes are designed for the computation of the MLE: a direct iteration scheme and a more sophisticated one based on invariant polynomials. Several examples are given to illustrate the usage of the methods. As expected, when the randomness is small (β small), the analytical results agree very well with the numerical ones. However, with the increase of randomness, the agreement becomes worse and higher order terms may chip in playing a role. In many cases, the increase of randomness brings in complex dependence of the MLE on β which can not be captured by an analytic expansion [2, 21]. When the current technique is used in the study of an Ising model with random onsite fields, the free energy is conveniently obtained with an analytic approximation in case of a strong coupling between neighboring spins.
The direct iteration scheme is very easy to implement but requires a special form of the major part of the random matrix which may not be determined so straightforwardly in practice. The second scheme based on invariant polynomials is very general but requires solution of a linear equation. Also, we assume that the major part of the random matrix has one dominant eigenvalue to guarantee a good convergence of the expansion. If there are multiple eigenvalues that have the same magnitude, the convergence of the polynomial coefficients is not guaranteed and we have to modify the method. On the other hand, as implemented in [27, 28], with the generating function formalism, a numerical scheme could be easily designed for the computation of the growth rate for any value of β, which is at least good for small matrices. For large matrices, however, a direct numerical computation seems unmanageable. Whether it is possible to extend either of the current two schemes to highly efficient numerical tools is an interesting question.
In the examples given above, matrices with dimensions only up to 4 are used in the computation although the formulation is valid for random matrices of higher dimensions. Of course, even the analytic computation could become cumbersome in high-dimensional cases, especially for the method based on invariant polynomials, if the involved random matrices are present in a large quantity. Nevertheless, even for a continuous distribution of matrices, the current scheme applies well [27], as demonstrated in the example in Section 3.3, as long as the involved integration is not hard to do.
In all the above computation, only the MLE is computed. How to generalize the current formulation to the evaluation of other Lyapunov exponents is still under investigation. Also, in all the calculations, we assume that the MLE exists which measures the exponential increase of the length of a typical vector following the dynamics determined by random matrix multiplication. However, in certain critical cases, this growth may not be exponential but follows a power law [21]. How to adjust the above computation to this case is still an open problem [29,30,31,32].